IMPSCORE Explained: A Learnable Metric for Implicitness in Language
A review of IMPSCORE, a reference-free metric for measuring implicitness in language using semantic and pragmatic divergence.
Language is not always what it seems—and this is precisely where NLP models struggle. While Large Language Models (LLMs) have become highly effective at capturing syntax and literal meaning, they often fail to understand the unspoken gap between what is said and what is actually meant.
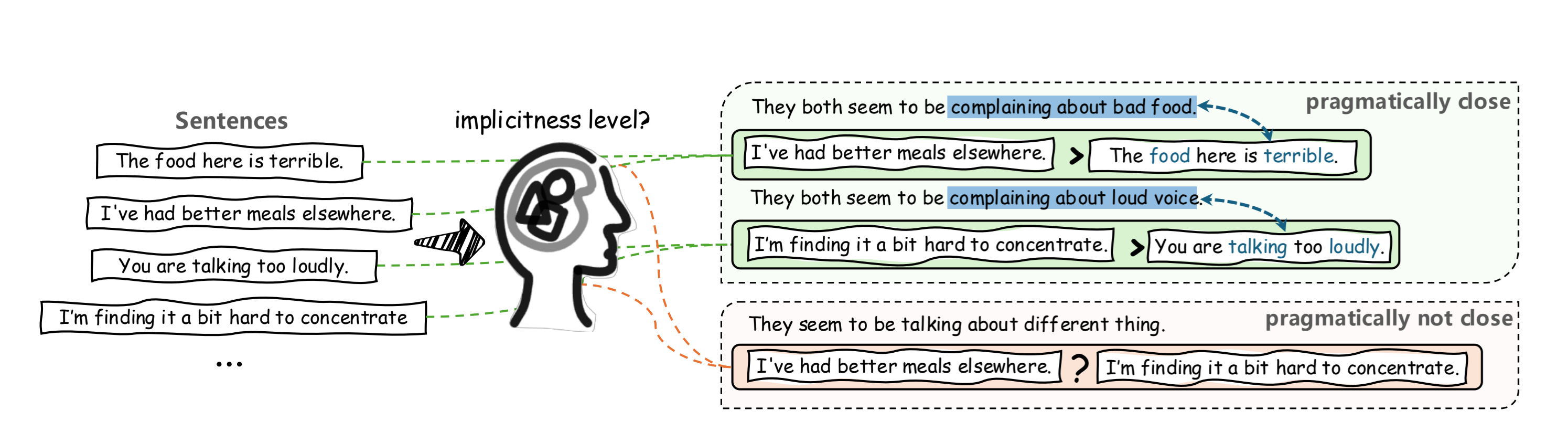
This work builds on foundational theories in linguistics, particularly those of H. P. Grice and Robyn Carston, which distinguish between semantic meaning and pragmatic interpretation.
For example, the sentence:
“I’m finding it a bit hard to concentrate”
literally expresses difficulty in focusing. However, in context, it may implicitly convey a complaint about someone being too loud.
In contrast:
“You are talking too loudly”
is an explicit statement where the intended meaning is directly expressed.
This illustrates a key phenomenon:
There exists a gap between semantic meaning (literal) and pragmatic meaning (intended).
Humans can easily infer such implicit intentions, but AI systems often interpret these sentences literally. Until now, there has been no reliable way to quantify how implicit a sentence is.
To address this, the paper introduces IMPSCORE, a metric designed to measure the level of implicitness in language.
1. The Core Problem: Measuring the Unspoken
Definition of Implicitness
The paper defines implicitness as the divergence between semantic meaning (literal) and pragmatic interpretation (intended meaning inferred from context).Limitations of Existing Evaluation
Traditional NLP evaluation methods rely on binary labels (implicit vs. explicit), which fail to capture the nuanced, continuous nature of human language.LLM Bottleneck
Although LLMs perform well on standard benchmarks, their performance degrades as the level of implicitness increases.
2. Introducing IMPSCORE
IMPSCORE is a reference-free, learnable metric that quantifies how implicit a sentence is—without requiring any ground-truth reference text.
Unlike traditional evaluation methods that compare outputs against human-written references, IMPSCORE evaluates a sentence based solely on its internal representation.
1) How It Works (The Framework)
Text Encoding
Each sentence is first converted into a dense vector representation using Sentence-BERT (all-mpnet-base-v2).- Dual Projection Spaces
The embedding is projected into two independent spaces:- Semantic space (literal meaning)
- Pragmatic space (intended meaning)
Space Alignment & Divergence
The pragmatic representation is transformed into the semantic space, and the distance between the two representations is computed.Implicitness Score
The final score is calculated using cosine distance:Larger distance → greater divergence → higher implicitness
In other words, the more a sentence “implies” rather than directly states, the higher its score.
Additionally, IMPSCORE includes a pragmatic distance metric to measure how close two sentences are in terms of intended meaning.
2) Training and Dataset
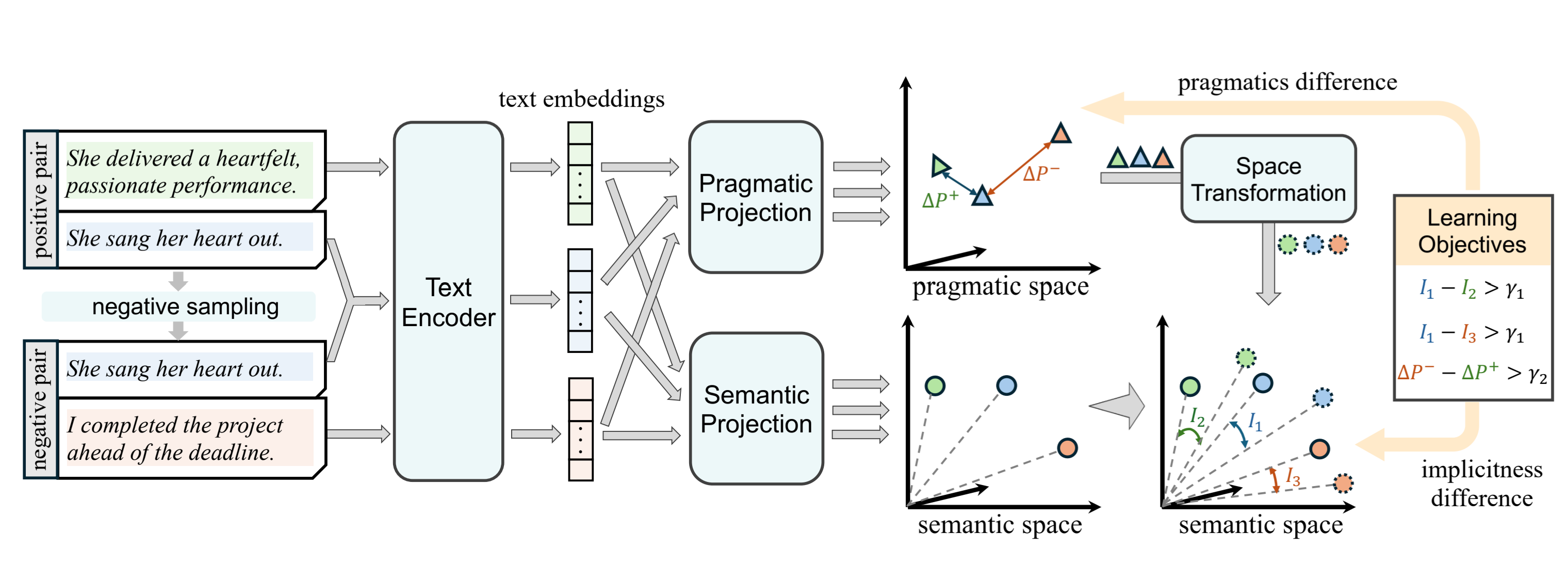
IMPSCORE is trained using pairwise contrastive learning.
Each training instance consists of:
- Positive Pair
- s₁: implicit sentence
- s₂: explicit sentence with similar meaning
- Negative Pair
- s₁: same implicit sentence
- s₃: explicit sentence with pragmatically distant meaning
Here:
- s₁ acts as the anchor
- s₂ represents pragmatically similar meaning
- s₃ represents distant meaning
The model is trained to learn two key behaviors:
- distinguish implicit sentences from explicit ones
- capture pragmatic similarity between sentences
The dataset consists of 112,580 (implicit, explicit) sentence pairs collected from 13 diverse sources.
3) Integration and Model Embodiment (Final Training Objective)
The final loss function is a weighted sum of $L_{imp}$ and $L_{prag}$, where $\alpha$, a predefined factor ranging from $[0, \infty)$, dictates the relative importance assigned to the learning of pragmatics.
Final Loss Formula
\[\mathcal{L}_{final}((s_{1}, s_{2}), (s_{1}, s_{3})) = \mathcal{L}_{imp}(s_{1}, s_{2}) + \mathcal{L}_{imp}(s_{1}, s_{3}) + \alpha \cdot \mathcal{L}_{prag}(s_{1}, s_{2}, s_{3})\]Detailed Components
$\mathcal{L}_{imp}$ (implicitness loss)
- Purpose:
Ensures that the implicit sentence ($s_1$) receives a higher score than both its explicit counterpart ($s_2$) and an unrelated explicit sentence ($s_3$).
$\mathcal{L}_{prag}$ (pragmatic loss)
- Purpose:
Encourages sentences with similar meanings ($s_1$, $s_2$) to be close in the pragmatic space, while pushing dissimilar sentences ($s_1$, $s_3$) farther apart.
$\alpha$ (Alpha - Hyperparameter)
- Role:
Controls the trade-off between:- learning accurate implicitness scores, and
- structuring the pragmatic space effectively.
- Higher $\alpha$ → more emphasis on pragmatic relationships
- Lower $\alpha$ → more emphasis on implicitness ranking
3. Key Findings & Applications
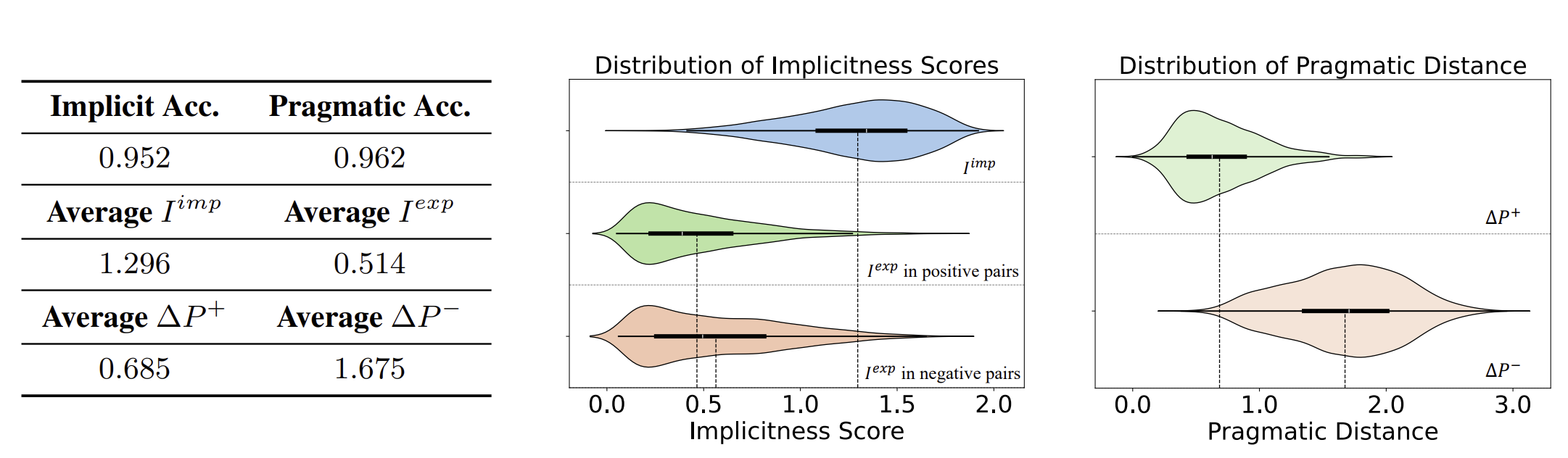
IMPSCORE achieves:
- Implicitness Accuracy > 95%
- Pragmatics Accuracy > 95%
This indicates that the model can reliably:
- assign higher scores to more implicit sentences
- distinguish between pragmatically similar and dissimilar sentence pairs
LLM Performance Analysis
When applied to evaluate LLMs:
- Performance consistently drops as implicitness increases
- Models struggle significantly with highly implicit content, especially in tasks like hate speech detection
This reveals a critical limitation:
LLMs may appear strong on benchmarks, but fail to understand subtle, indirect language.
Dataset Insights
Adversarial datasets contain the highest implicitness
- Example (illustrative): “We should provide them with a one-way ticket back to where they came from.”
- Explanation: Instead of explicitly saying “we should deport them,” it uses the metaphor of a “one-way ticket,” strongly implying exclusion of the target group.
- Lexicon-based datasets (e.g., Davidson) show low implicitness
- Example (illustrative): “I hate these [slur] people.”
- Explanation: Overt hate terms and explicit hostility are stated directly, making the sentence highly explicit.
- LLM-generated data (e.g., ToxiGen) tends to be less implicit than human-written text
- Human-written: “They are taking over our neighborhoods.”(subtly implies threat and anxiety)
- LLM-generated: “I do not like this group of people because they are bad.” (remains flat and explicitly judgmental, with little nuance)
This suggests that current LLMs struggle to reproduce human-level pragmatic nuance.
4. Conclusion and Future Directions
IMPSCORE introduces a new way to quantify implicit meaning, bridging a critical gap in NLP evaluation.
Key contributions include:
- A continuous metric for implicitness
- Strong correlation with human judgment
- Efficient, interpretable alternative to LLM-based evaluators
Looking forward, IMPSCORE has strong potential in:
- Reinforcement learning (e.g., RLHF reward signals)
- Socially-aware AI systems
- Implicit intent detection and safety evaluation
Future work includes:
- expanding datasets (including multilingual data)
- improving encoder architectures
- extending evaluation with broader user studies
IMPSCORE offers a practical, reference-free way to quantify “reading between the lines,” enabling better RLHF signals and more socially aware AI systems that can reason about implicit meaning.